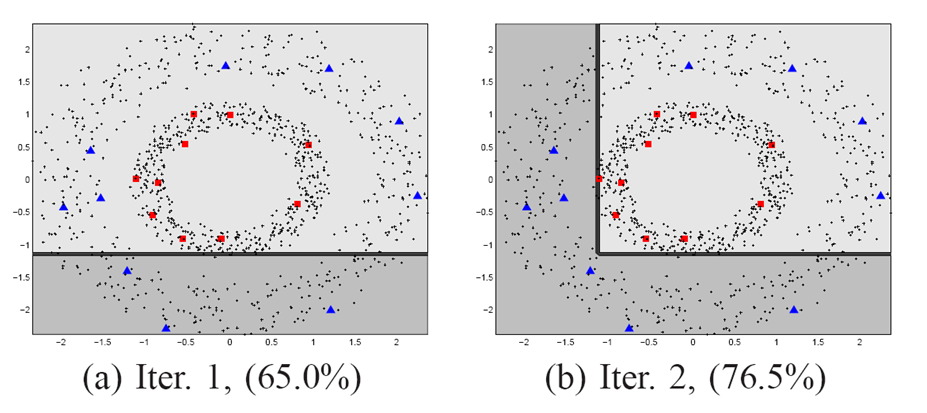
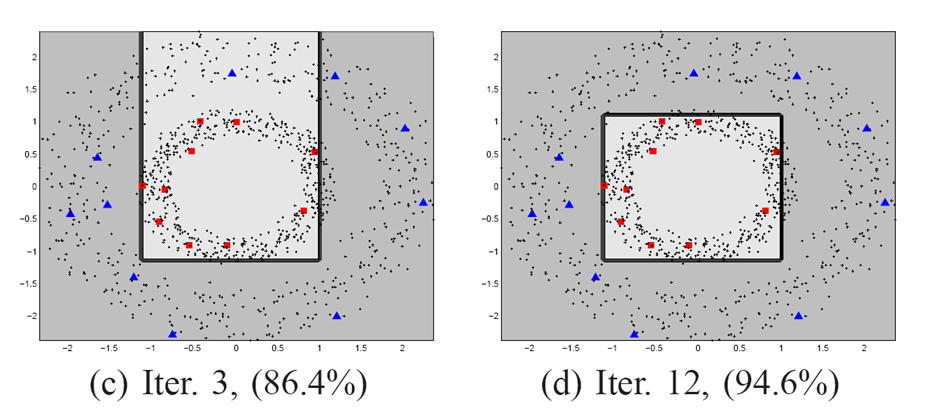
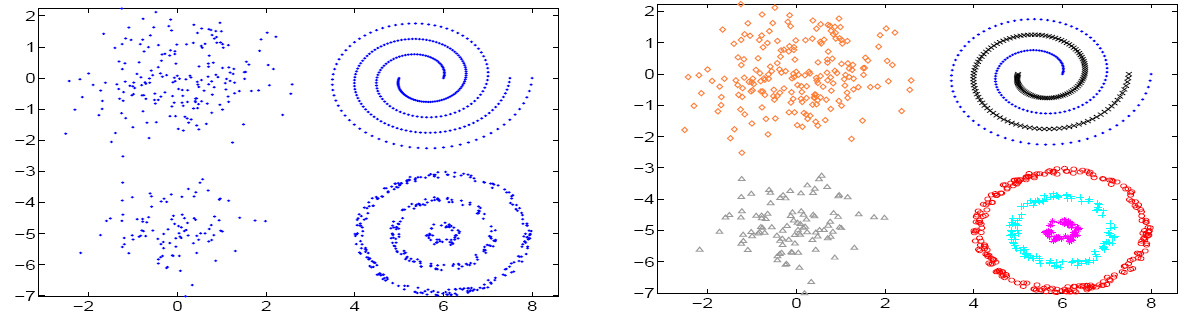
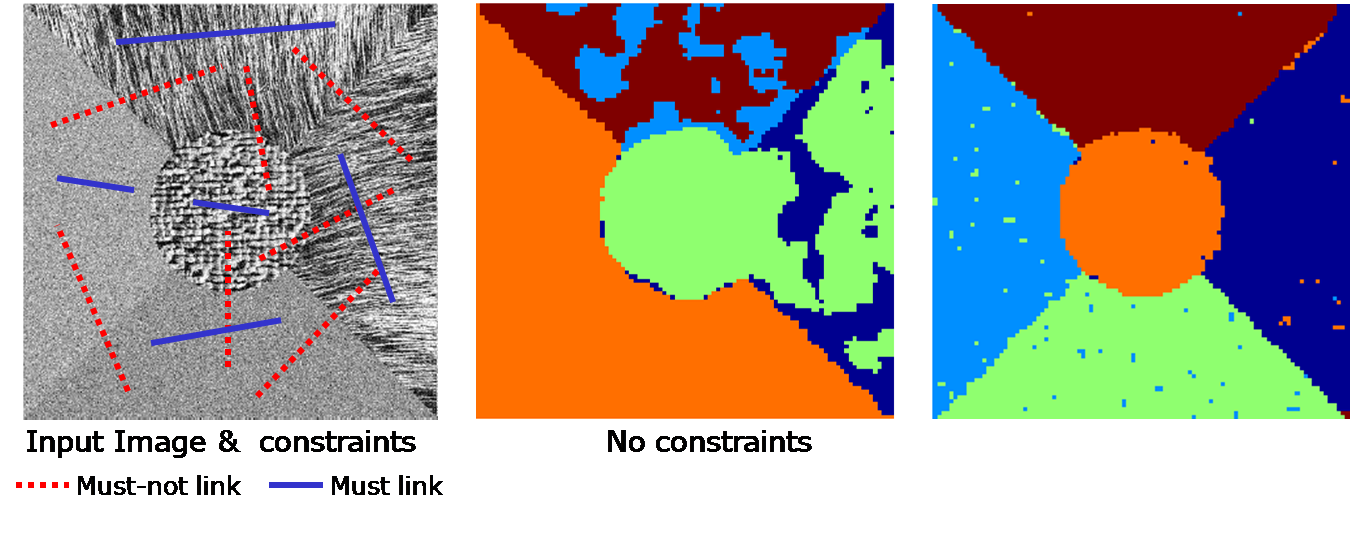
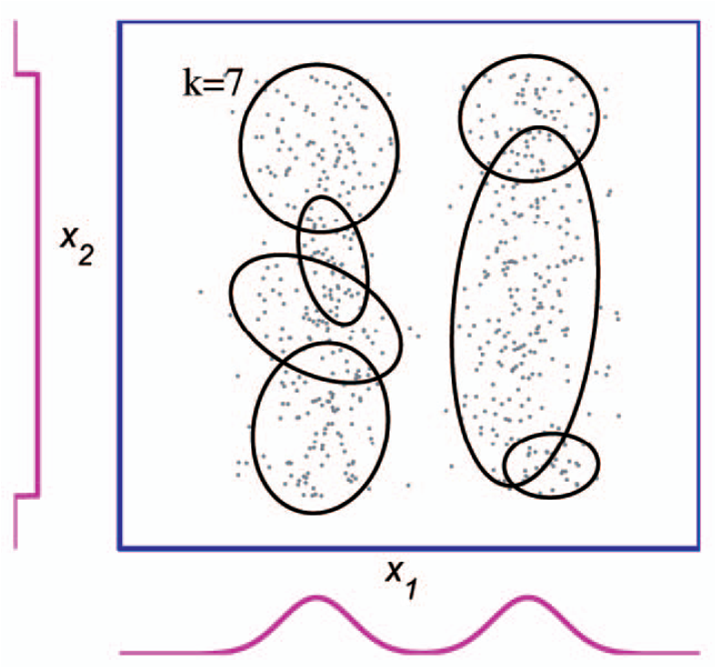
|
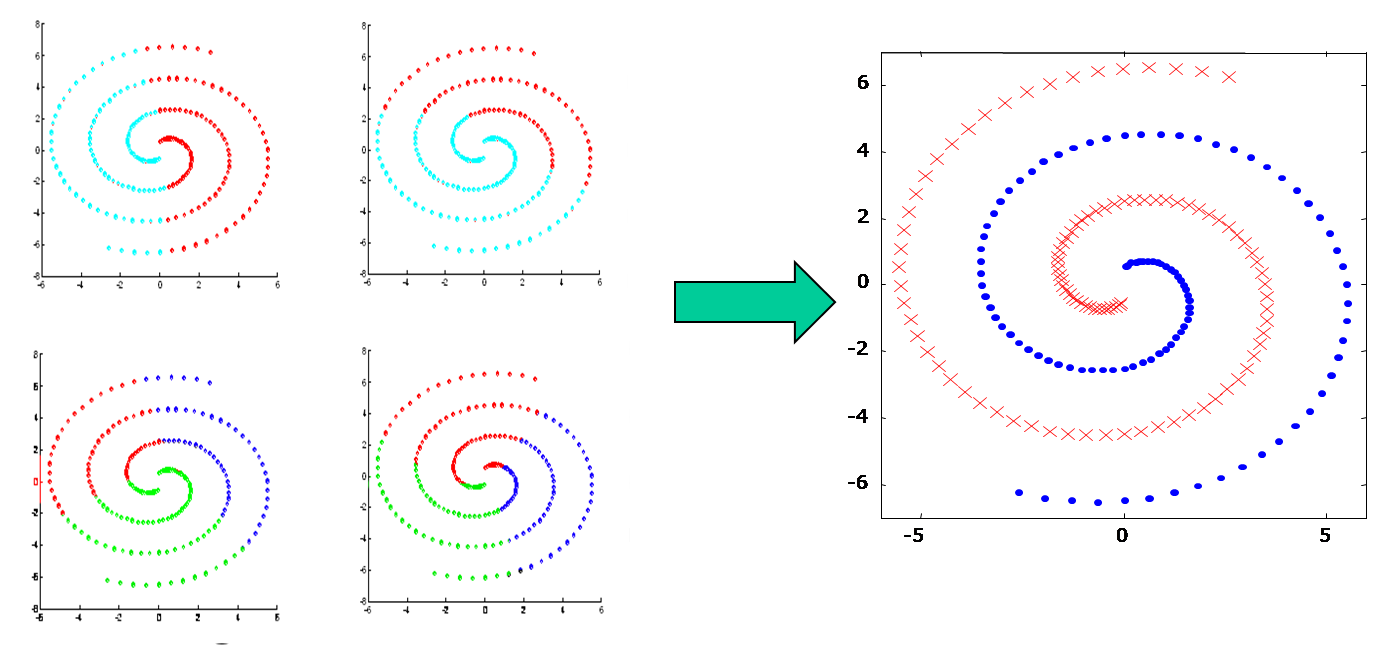
Combination of multiple classifiers in supervised
classification has achieved great success and it is becoming one of
the standard techniques in pattern recognition. However, little has been
done to explore how to combine data partitions generated by different
clustering algorithms. The following papers investigate different issues
on combining the outputs of multiple clustering algorithms.
- A. Fred, A.K. Jain. Combining Multiple Clustering Using
Evidence Accumulation. IEEE Transactions on Pattern Analysis and
Machine Intelligence, vol. 27, number 6, pp. 835-850, 2005. (Abstract
in IEEE explore)
- A. Topchy, A.K. Jain,W. Punch. Clustering Ensembles: Models of
Consensus and Weak Partitions. To appear in IEEE Transactions on
Pattern Analysis and Machine Intelligence (under review).
- A. Topchy, M. H. Law. A.K. Jain, A. Fred. Analysis of Consensus Partition in
Cluster Ensemble. In Proceedings of The Fourth IEEE International
Conference on Data Mining, pp. 225-232, Brighton, UK, November
01-04, 2004.
- A. Topchy, B. Minaei, A.K. Jain, W. Punch. "Adaptive clustering Ensembles", in
Proceedings of the International Conference on Pattern
Recognition, Cambridge, United Kingdom, August 23-26, 2004.
- A. Topchy, A.K. Jain, W. Punch, "A Mixture Model of Clustering
Ensembles", in Proceedings of the SIAM International Conference
on Data Mining, Lake Buena Vista, Florida, April 22-24, 2004.
- B. Minaei, A. Topchy, and W. Punch, Ensembles of Partitions via Data Resampling, in
Proceedings of the International Conference on Information
Technology: Coding and Computing, ITCC 2004, Las Vegas, April 2004
- A. Topchy, A.K. Jain, W. Punch, "Combining Multiple Weak
Clusterings", in Proceedings of the IEEE International Conf. Data
Mining, pp. 331-338, Melbourne, Florida, USA, November 19-22 2003.
- A. Fred, A.K. Jain, "Data Clustering Using Evidence
Accumulation", in Proceedings of the International Conference on
Pattern Recognition (ICPR), Quebec City, August 11-15 2002.
- A. Fred, A.K. Jain, "Evidence
Accumulation Clustering based on the K-means algorithm", in
Proceedings of the International Workshops on Structural and
Syntactic Pattern Recognition (SSPR), Windsor, Canada, August 6-9
2002.
|